トップページ > IPO 予測モデル
|
機械学習を用いてIPOの初値騰落率を予測する
作成日:2017年3月6日
機械学習を用いてIPOの初値騰落率を予測しよう。 筆者は、2012年から、AIの一種である機械学習を組み込んだ予測モデルを用いて、初値騰落率の予測情報を公開している。この予測モデルは、新規上場時に得られる6つの基本的な情報(以下で説明)だけを用いて、初値騰落率を予測するものである。公開してから既に4年を経過し、一定の予測力を継続して示していることから、ここでは、予測モデルの開発に至った経緯とその基本的な考え方について、簡単な説明を加えることにする。 予測モデルの開発経緯 もし、市場にアノマリーが存在しなければ、株式の公開価格と初値は一致するはずである。なぜなら、これらは共に企業の財務や成長性などのファンダメンタルな情報をベースにして決定されているはずだからだ。しかし、実際の初値は、公開価格より平均的に高くなる傾向がある。投資家、新規上場企業、幹事証券会社の誰かがミスプライスしているのだ。 そこで、新規上場時に得られる基本的な情報(市場からの調達額=公開株数×公開価格、上場する市場、業種、主幹事など)を用いて、初値騰落率のクロス集計を行ってみた。そうすると、カテゴリー間で初値騰落率に有意な差異があることが確認できたのである。IPOの初値騰落率はこれらの基本的な情報だけでもある程度説明できるのではないか。これが、機械学習を用いた予測モデルを開発することになったきっかけである。(もともとは、予測モデルは、個人で初値投資をするために開発したものである。しかし、ブックビルディングに参加してもなかなか当選できなかったため、その予測値をネット上に公開することにした。) 予測モデルの基本的な考え方 予測モデルは、新規上場時に得られる基本的な情報を説明変数として、機械学習を用いて初値騰落率を予測するものである。 説明変数は、試行錯誤の上で、最終的に以下の6つとした。
予測値は、初値騰落率をA(+100%以上)、B(+30%以上+100%未満)、C(+30%未満)の3つのカテゴリーに分けて、初値騰落率がそれぞれのカテゴリーに属する可能性を確率(%)で表すことにした。 予測値の表示例
買付余力の制約はあるものの、一定以上のリターンが見込まれれば、投資家はブックビルディングに参加すると思われる。従って、投資家にとってはA、B、Cの区別があれば十分であろう。(以下の「ブックビルディング参加基準の例」を参照)
予測対象の新規上場企業は、ブックビルディング開始日を経過したものである。ブックビルディング期間中は説明変数6の「公開価格」が決定していないため、この期間中は説明変数1~5のみで予測を行った(「市場からの調達額」は暫定的に仮条件上限価格×公開株数とした)。ブックビルディング期間中の予測を「事前予測」、公開価格決定後の予測を「確定予測」とした。 なお、企業の財務や成長性などのファンダメンタルな情報を説明変数に加えなくても予測力が得られるのは、これらの情報は概ね公開価格に織り込まれていると考えられるからである。 おわりに 以下の図は、予測モデル(および、そのベンチマーク)の各年の的中率の推移を示したものである。これによって、予測モデルを使用することで的中率が20%程度上がることが確認できる。(的中率、および、ベンチマークの考え方は「IPO予測値の検証」を参照) 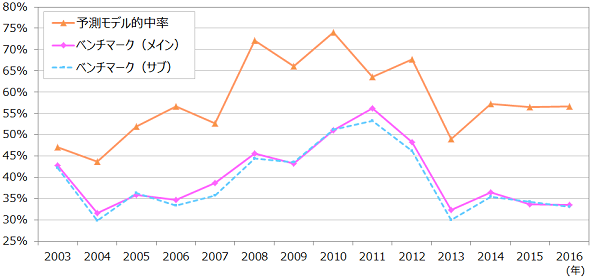 重要なことは、予測モデルが予測力を示すこともさることながら、6つの説明変数が一定の説明力を有するということである。これらは新規上場時に簡単に得られる情報であり、また、理解するのはそんなに難しくない情報である。初値投資は、基本的な情報を吟味するだけでも、パフォーマンスの向上が期待できそうである。 |